# Arquitetura
## Arquitetura
* [Arquitetura](#arquitetura)
* [Visão Macro](#visao-macro)
* [API](#api)
* [Entrada](#entrada)
* [Adaptação](#adaptacao)
* [Indexação](#indexacao)
* [Filtro](#filtro)
* [Saída](#saída)
* [Funcionamento](#funcionamento)
* [Novo pipeline](#novo-pipeline)
* [Fluxo do pipeline](#fluxo-do-pipeline)
* [Input HTTP](#input-http)
* [Input Batching](#input-batching)
* [Input Streaming](#input-streaming)
* [Adapting](#adapting)
* [Syndicating](#syndicating)
* [Exporter](#exporter)
* [Filtering](#filtering)
* [Fluxo reduzido](#fluxo-reduzido)
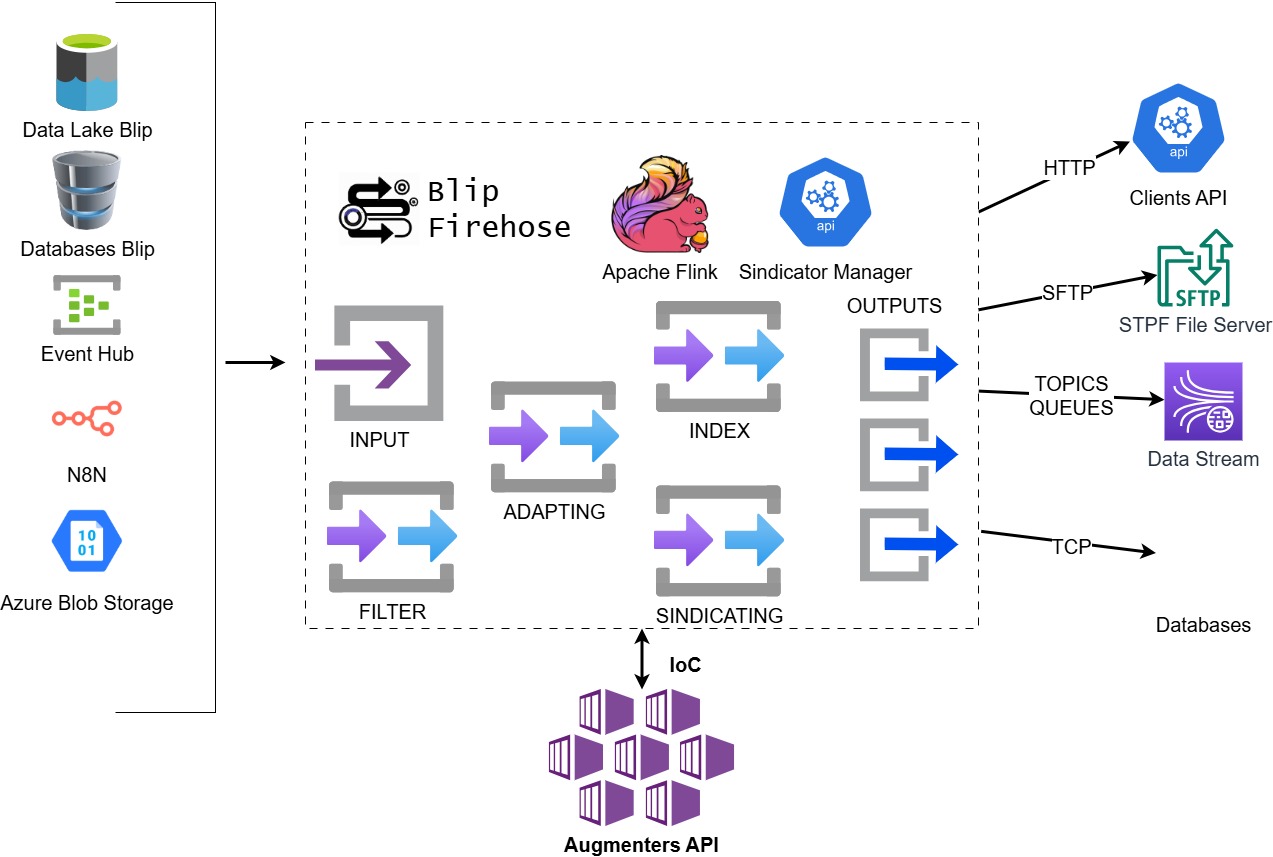
O diagrama a seguir demonstra a visão macro da plataforma.
### Visão Macro
Ela é dividida nas seguintes partes:
#### API
A aplicação golang sindicator-manager possui a API responsável pelo CRUD das configurações com os pipelines.
#### Entrada
Conecta-se com diferentes tipos de entrada de dados.
#### Adaptação
Aplica transformações no dado trafegado. Essas transformações podem ser realizadas através de inversão de controle (chamando-se uma API externa, por exemplo) ou por meio de processamento em streaming (usando o ).
#### Indexação
Permite indexar dados para serem filtrados e entregues posteriormente.
#### Filtro
Permite filtrar dados previamente indexados para serem entregues.
#### Saída
Conecta-se com diferentes tipos de saída para entrega de dados.
## Funcionamento
Descreve em detalhes cada etapa do fluxo desde a criação do pipeline até o fluxo das mensagens nesse pipeline.
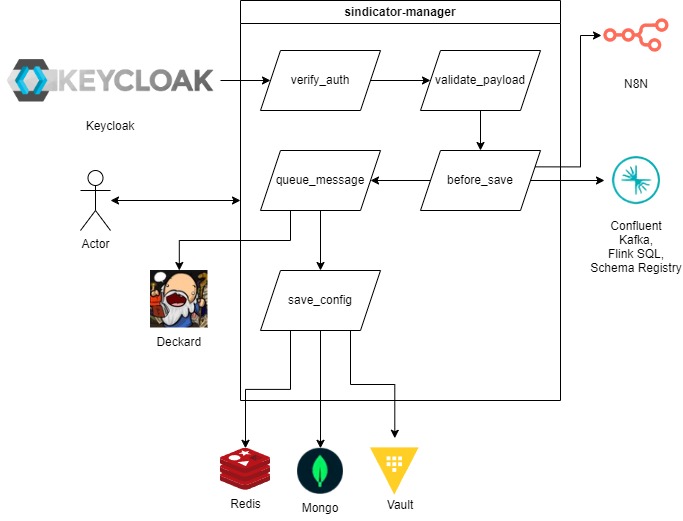
### Novo pipeline
O diagrama a seguir ilustra as conexões realizadas durante a criação de um novo pipeline:
A primeira etapa consiste em verificar a autenticação do usuário. O [Keycloak](https://www.keycloak.org/) é utilizado como autenticador nessa etapa. Ele também é utilizado como gerenciador de identidade.
Uma vez autenticado ocorre a validação do payload da configuração. Utilizamos a [lib de validação](https://pkg.go.dev/github.com/go-playground/validator/v10#section-readme) para esse fim.
Depois são realizadas requisições em APIs externas dependendo do que está sendo configurado no pipeline.
* Caso seja uma entrada do tipo [N8N](https://n8n.io/) a API é utilizada para registrar o workflow e credenciais para recuperar os dados;
* Caso possua um processamento em streaming com Flink configurado as [APIs de Schema Registry, Kafka e Flink SQL da Confluent](https://docs.confluent.io/cloud/current/api.html) são utilizadas para configurar os pipelines de processamento em streaming;
* Caso seja um input do tipo streaming (Ex: KAFKA, GOOGLE\_CLOUD\_PUBSUB), é adicionada uma mensagem na fila **dynamic\_input\_streamming** do [Deckard](https://github.com/takenet/deckard) que será utilizada posteriormente pelo fluxo do pipeline para realizar a conexão com a entrada e recuperar as mensagens;
* Caso seja um input do tipo batching (Ex: SQL, DELTA\_SHARING), é adicionada uma mensagem na fila **dynamic\_input\_batching** do [Deckard](https://github.com/takenet/deckard) que será utilizada posteriormente pelo fluxo do pipeline para realizar a conexão com a entrada e recuperar as mensagens.
Por fim a configuração é salva nos repositórios.
* O [Mongo](https://www.mongodb.com/) é utilizado para armazenar a configuração do pipeline de forma persistente;
* O [Redis](https://redis.io/) utilizado para armazenar a configuração do pipeline para acesso rápido. As configurações são salvas sem TTL e em qualquer alteração toda a configuração é substituída nele;
* O [Hashicorp Vault](https://www.vaultproject.io/) é utilizado para guardar os segredos (tokens, senhas, credenciais, ...) da configuração. Esses dados são salvos encriptados em **aes** no esquema **ctr**, a chave e vetor de criptografia só são conhecidos pela aplicação do sindicator-manager.
O payload de resposta para o usuário em caso de sucesso aplica uma máscara nos campos com segredos.
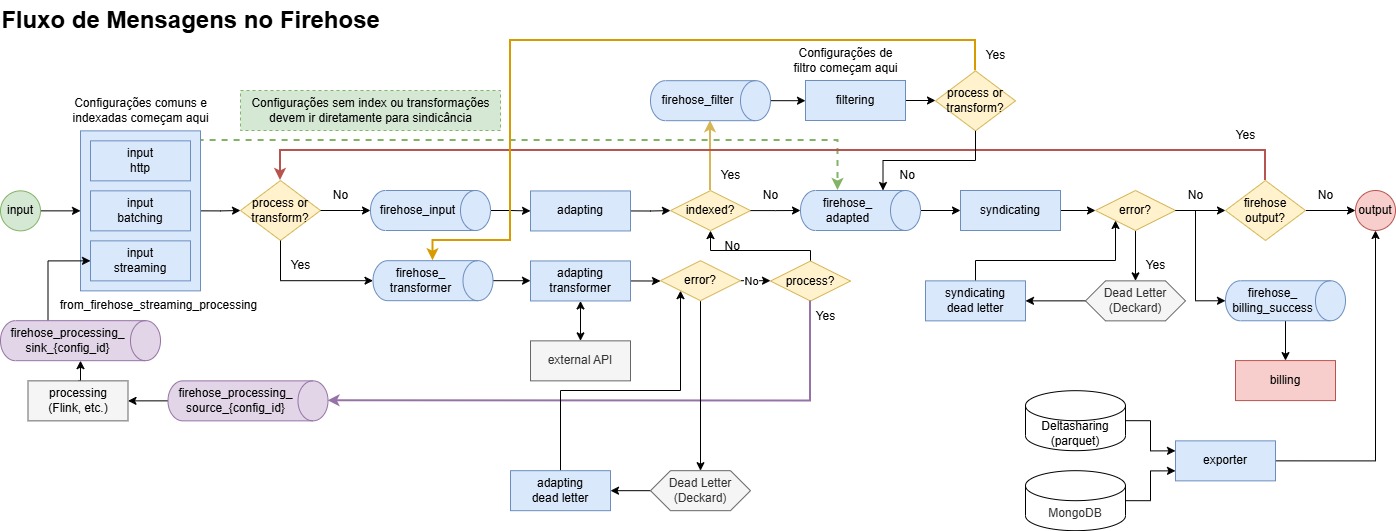
### Fluxo do pipeline
O diagrama a seguir ilustra como é o fluxo das mensagens em um pipeline:
#### Input HTTP
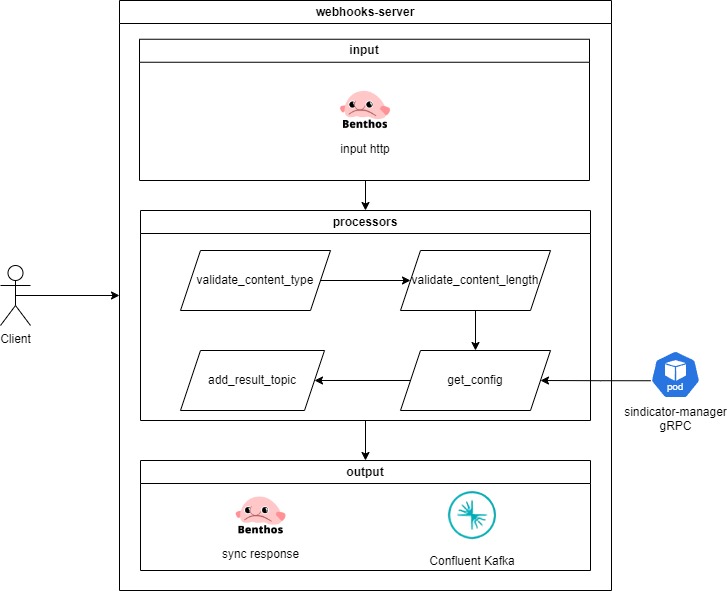
Nesse caso as mensagens são enviadas para o fluxo de um pipeline a partir da [API HTTP do Firehose](https://docs-firehose.blip.ai/configuracoes/configuracao-de-entrada/http). É necessário que o usuário tenha criado uma configuração de pipeline previamente pois o id do pipeline, além da autenticação é obrigatório para enviar as mensagens.
A aplicação que recebe essas mensagens é o **webhooks-server**. O fluxo que ele executa é o seguinte:
Em um primeiro momento a aplicação valida se requisição contém o **content-type** do payload enviado.
Depois verifica se o tamanho do payload é inferior a 1MB.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual a mensagem foi enviada.
A partir da configuração define-se para qual etapa (tópico Kafka) a mensagem será enviada para seguir no fluxo. A verificação ocorre nessa ordem:
1. Se a configuração possui algum estágio de transformação ou processamento em streaming a mensagem segue para o tópico: **firehose\_transformer**;
2. Caso contrário a mensagem segue para o tópico: **firehose\_input**.
Por fim ocorre o retorno do status da requisição para o cliente.
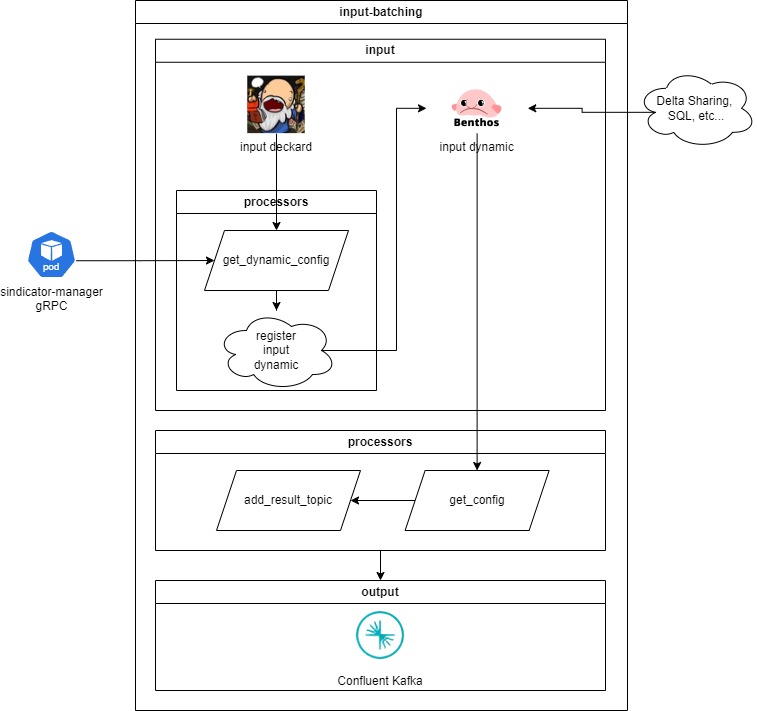
#### Input Batching
Nesse caso o Firehose se conecta a entrada cadastrada na configuração do pipeline e recupera as mensagens em lotes.
A aplicação responsável por essa entrada é o **input-batching**. O fluxo que ela executa é o seguinte:
Inicialmente a aplicação recupera uma mensagem com o id da configuração de pipeline cadastrada a partir da fila do deckard: **dynamic\_input\_batching**.
A mesma mensagem é retornada pelo deckard a cada `30s` mas um batch só é iniciado quando o batch anterior for finalizado, a mensagem vai sendo ignorada enquanto isso. O timeout de processamento do batch é de 30 minutos. Nesse caso a mensagem é liberada para que o mesmo batching seja processado novamente.
A partir do id da configuração é realizada uma requisição gRPC no **sindicator-manager** para recuperar a configuração dinâmica do pipeline. A resposta dessa requisição contém todos os dados de autenticação necessários para se conectar com a entrada em questão (Ex: SQL, Delta Sharing, ...).
É realizado então o registro da entrada de forma dinâmica utilizando a [requisição HTTP do Benthos](https://docs.redpanda.com/redpanda-connect/components/inputs/dynamic/) no localhost já que a aplicação possui um http server pois possui uma entrada dinâmica.
Uma vez que a entrada é registrada o consumo das mensagens já começa a acontecer.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual a mensagem está trafegando.
A partir da configuração define-se para qual etapa (tópico Kafka) a mensagem será enviada para seguir no fluxo. A verificação ocorre nessa ordem:
1. Se a configuração possui algum estágio de transformação ou processamento em streaming a mensagem segue para o tópico: **firehose\_transformer**;
2. Caso contrário a mensagem segue para o tópico: **firehose\_input**.
Quando todas as mensagens são consumidas ocorre a atualização do breakpoint da mensagem no deckard para que o próximo batch seja consumido da entrada a partir do ponto atual desconsiderando o que já foi consumido.
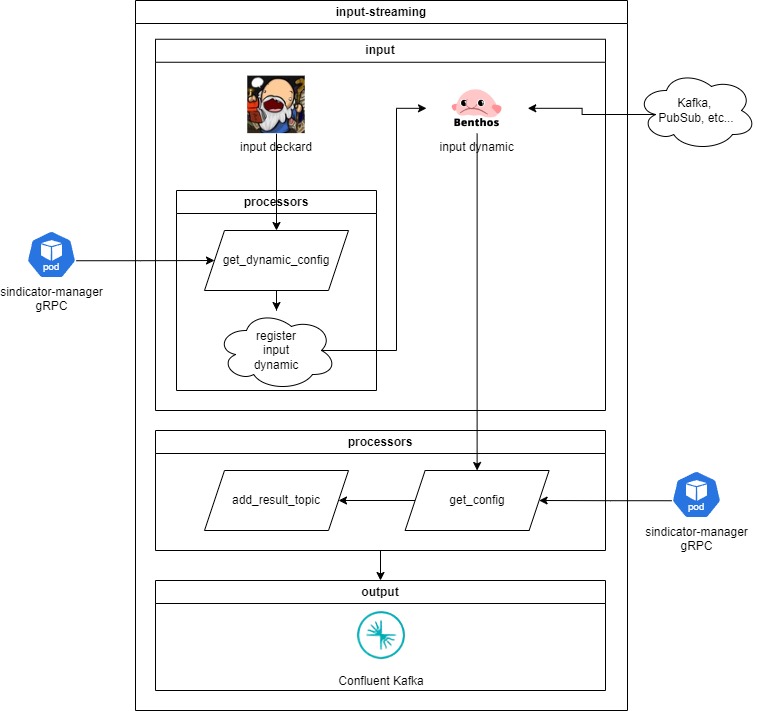
#### Input Streaming
Nesse caso o Firehose se conecta a entrada cadastrada na configuração do pipeline e recupera as mensagens de forma contínua a partir do streaming de entrada.
A aplicação responsável por essa entrada é o **input-streamming**. O fluxo que ela executa é o seguinte:
Inicialmente a aplicação recupera uma mensagem com o id da configuração de pipeline cadastrada a partir da fila do deckard: **dynamic\_input\_streamming**.
A partir do id da configuração é realizada uma requisição gRPC no **sindicator-manager** para recuperar a configuração dinâmica do pipeline. A resposta dessa requisição contém todos os dados de autenticação necessários para se conectar com a entrada em questão (Ex: Kafka, GCP PubSub, ...). Esse processo se repete a cada 15 minutos para garantir que a configuração está atualizada e que a entrada será removida caso o pipeline em questão seja excluído ou mesmo alterado para um outro tipo de entrada.
É realizado então o registro da entrada de forma dinâmica utilizando a [requisição HTTP do Benthos](https://docs.redpanda.com/redpanda-connect/components/inputs/dynamic/) no localhost já que a aplicação possui um http server pois possui uma entrada dinâmica.
Uma vez que a entrada é registrada o consumo das mensagens já começa a acontecer.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual a mensagem está trafegando.
A partir da configuração define-se para qual etapa (tópico Kafka) a mensagem será enviada para seguir no fluxo. A verificação ocorre nessa ordem:
1. Se a configuração possui algum estágio de transformação ou processamento em streaming a mensagem segue para o tópico: **firehose\_transformer**;
2. Caso contrário a mensagem segue para o tópico: **firehose\_input**.
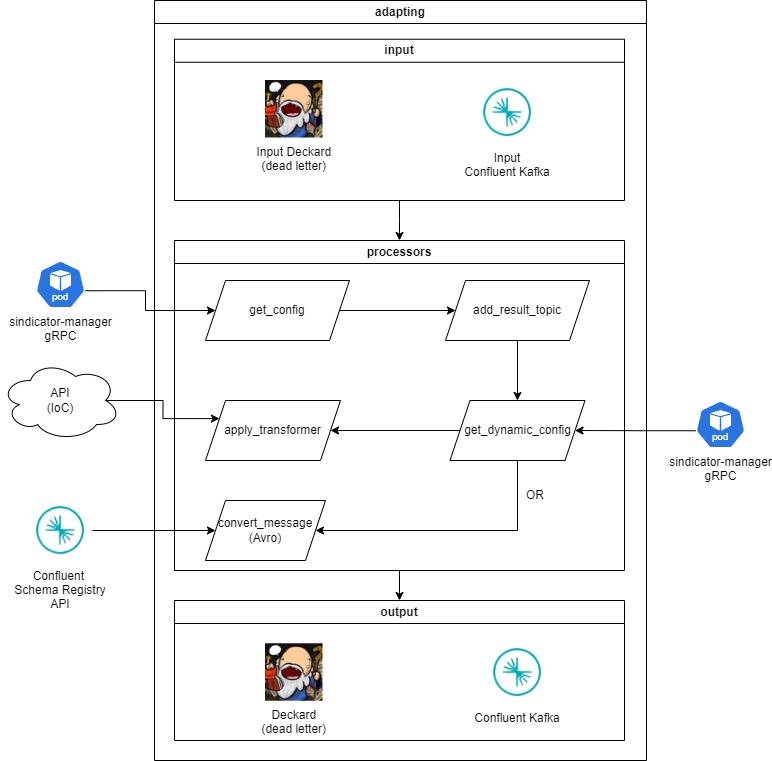
#### Adapting
Realiza transformações configuradas no pipeline em cada mensagem trafegada.
A aplicação responsável é o **adapting-transformer-pipeline**. Ela se conecta ao tópico **firehose\_transformer** populado pelos inputs caso a configuração possua etapa de transformação ou processamento em streaming.
Também existe a aplicação **adapting-pipeline** que executa o mesmo pipeline, porém não aplica transformações nas mensagens e segue com elas no fluxo. Ela se conecta ao tópico **firehose\_input**. Isso é necessário devido a infraestrutura de tópico Kafka único. Dessa forma, configurações de pipeline que não possuem etapas de transformação seguem por um fluxo apartado (tópico kafka diferente) e não são prejudicadas por latência de configurações que executam transformações.
O fluxo que ela executa é o seguinte:
Em um primeiro momento é realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual a mensagem está trafegando.
A partir da configuração define-se para qual etapa (tópico Kafka) a mensagem será enviada para seguir no fluxo. A verificação ocorre nessa ordem:
1. Se a configuração possui um estágio processamento em streaming a mensagem segue para o tópico: **firehose*****processing\_source*****{CONFIG-ID}**;
2. Se a configuração possui um estágio de indexação a mensagem segue para o tópico: **firehose\_filter**. Nesse caso é adicionado um metadado nas mensagens (**firehose\_index**) com um json contendo os campos que poderão ser filtrados posteriormente por uma configuração de filtro.
3. Caso contrário a mensagem segue para o tópico: **firehose\_adapted**.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar a configuração dinâmica do pipeline. A resposta dessa requisição contém todos os dados de autenticação necessários para se conectar com as APIs externas caso exista um estágio de transformação com requisições à APIs externas.
A partir da configuração dinâmica são executadas as etapas de transformação na mensagem seguindo o workflow configurado no pipeline. Nesse momento são realizadas as requisições em APIs externas, se necessário.
Se uma configuração possui estágio de processamento em streaming é realizado a conversão das mensagens para o formato Avro que será enviado para o tópico de processamento em streaming com Flink. A API de Schema Registry da Confluent é chamada nesse momento para recuperar o schema Avro que será usado na conversão das mensagens.
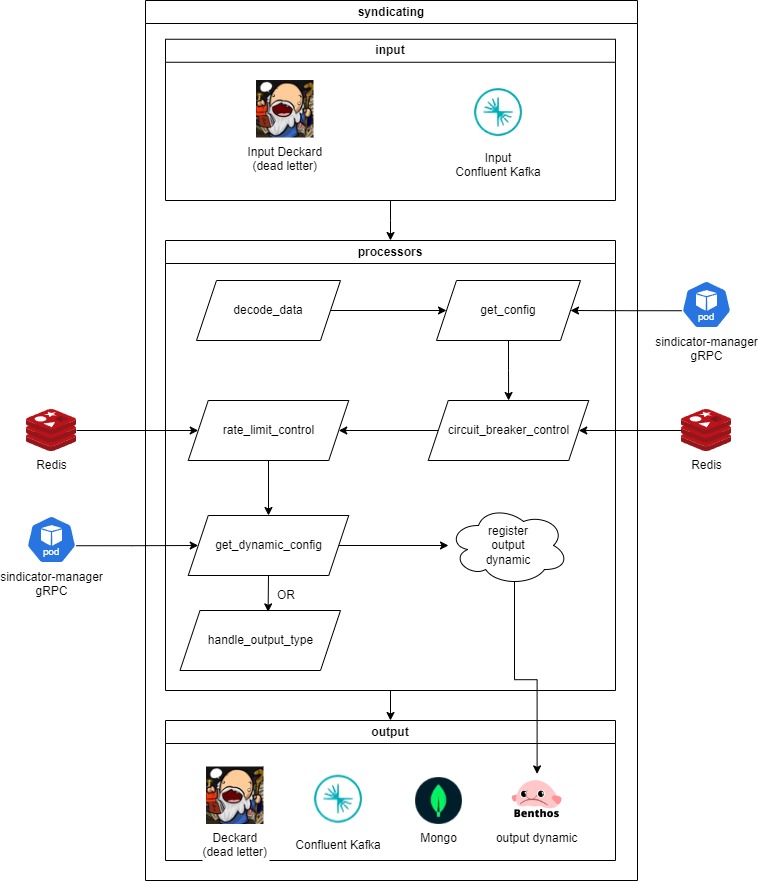
#### Syndicating
Envia os dados de forma transacional para a sindicância de destino (saída) configurada no pipeline.
A aplicação responsável é o **syndicating-pipeline**. O fluxo que ela executa é o seguinte:
Em um primeiro momento é realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual a mensagem está trafegando.
É realizado então um controle de *circuit breaker* utilizando o Redis que verifica se mensagens de uma configuração estão resultando em erros na entrega. Caso uma configuração apresente pelo menos 5 erros em 1 minuto ela é penalizada por 15 minutos e suas mensagens são enviadas diretamente para o dead letter pra que sejam entregues posteriormente a medida que o dead letter vai sendo consumido.
Também existe um controle de *rate limit* utilizando o Redis, nesse caso o cliente configura no output uma taxa de entrega com quantidade de mensagens por tempo e a aplicação respeita esse *throughput* enviando as mensagens para o dead letter para que sejam entregues posteriormente a medida que o dead letter vai sendo consumido e respeitando o rate limit configurado.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar a configuração dinâmica do pipeline. A resposta dessa requisição contém todos os dados de autenticação necessários para se conectar com a saída em questão (Ex: Kafka, GCP PubSub, ...), caso exista. Esse processo se repeta a cada 1 minuto para garantir que a configuração da saída está atualizada.
Caso exista uma configuração dinâmica de saída é realizado o registro da saída de forma dinâmica utilizando a [requisição HTTP do Benthos](https://docs.redpanda.com/redpanda-connect/components/outputs/dynamic/) no localhost já que a aplicação possui um http server pois possui um *output* dinâmico.
Uma vez que a saída é registrada as mensagens já podem ser enviadas. A aplicação também envia um evento para o tópico de billing que será utilizado para contabilizar as mensagens entregues para uma configuração.
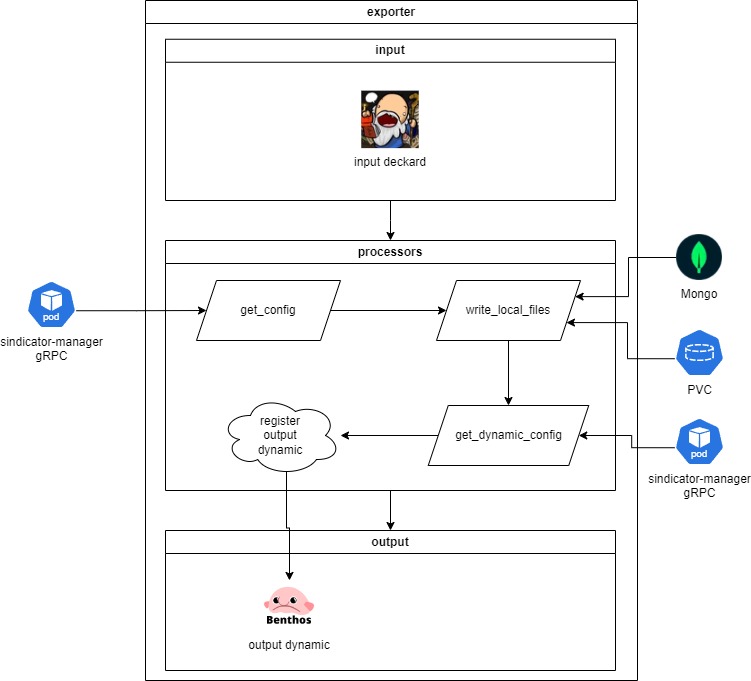
#### Exporter
Envia os dados agregados em arquivos (Ex: csv, json) para a sindicância de destino (saída) configurada no pipeline.
A aplicação responsável é o **exporter-pipeline**. O fluxo que ela executa é o seguinte:
Inicialmente a aplicação recupera uma mensagem com o id da configuração de pipeline cadastrada a partir de uma das filas do deckard: **export\_mongo\_messages** ou **export\_parquet\_messages**.
Então é realizada então uma requisição gRPC no **sindicator-manager** para recuperar os dados da configuração do pipeline para a qual os dados serão enviados.
O próximo passo é agregar os dados a serem entregues em arquivos em um formato específico (Ex: csv, json) e escrever esses arquivos em disco no diretório temporário.
É realizada então uma requisição gRPC no **sindicator-manager** para recuperar a configuração dinâmica do pipeline. A resposta dessa requisição contém todos os dados de autenticação necessários para se conectar com a saída em questão (Ex: AWS S3, GCP Storage, SFTP, ...). Esse processo se repete a cada 1 minuto para garantir que a configuração da saída está atualizada.
Caso exista uma configuração dinâmica de saída é realizado o registro da saída de forma dinâmica utilizando a [requisição HTTP do Benthos](https://docs.redpanda.com/redpanda-connect/components/outputs/dynamic/) no localhost já que a aplicação possui um http server pois possui um *output* dinâmico.
Uma vez que a saída é registrada as mensagens os arquivos são enviados.
#### Filtering
Filtra mensagens indexadas.
A aplicação responsável é o **filtering-pipeline**. O fluxo que ela executa é o seguinte:
A cada 1 minuto a aplicação realiza uma requisição gRPC no **sindicator-manager** para recuperar todas as configurações de pipeline que possuem filtro. De posse dessas configurações é executado um filtro em cada mensagem existente no tópico de mensagens indexadas (**firehose\_filter**) verificando quais configurações casam com a mensagem.
Caso a mensagem seja filtrada para pelo menos uma configuração de pipeline é realizada uma requisição gRPC no **sindicator-manager** para recuperar os dados de cada uma dessas configurações.
A partir da configuração define-se para qual etapa (tópico Kafka) a mensagem será enviada para seguir no fluxo. A verificação ocorre nessa ordem:
1. Se a configuração possui algum estágio de transformação ou processamento em streaming a mensagem segue para o tópico: **firehose\_transformer**;
2. Caso contrário a mensagem segue para o tópico: **firehose\_adapted**.
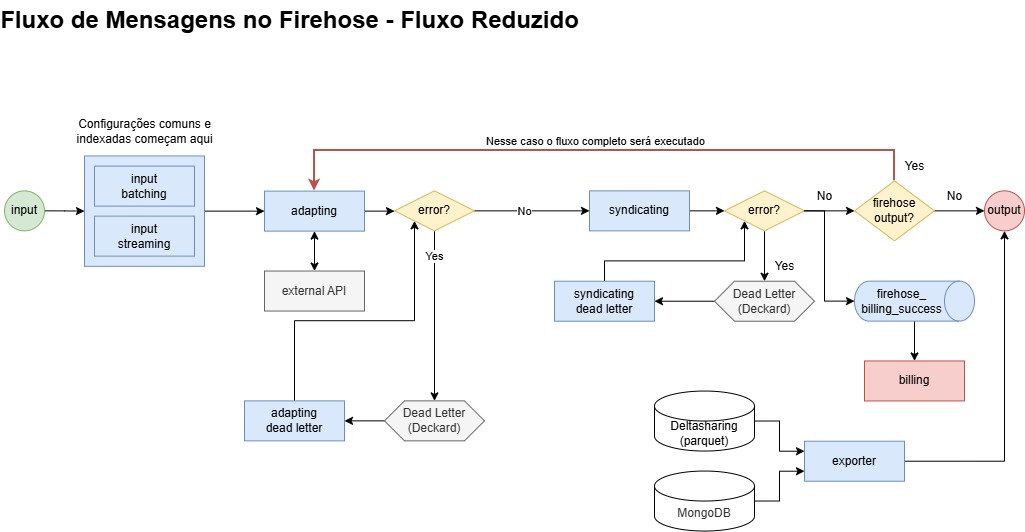
### Fluxo reduzido
O diagrama a seguir ilustra como é o fluxo reduzido do pipeline, ou seja, quando os tópicos kafka intermediários não são utilizados na execução e o dado trafega diretamente da entrada para a saída.
Nesse fluxo as camadas de entrada, adaptação e sindicância de destino estão presentes em um mesmo pipeline de execução.
Os mecanismos de garantia de entrega das mensagens ainda estão presentes nesse fluxo.
Ele é limitado a entradas do tipo batching ou streaming (não suporta HTTP), além de não suportar filtro, índice ou processamento em streaming.